
How AI Systems Reason Through Process-Level Evaluation and Reliable Assessment

Shubhankar Kahali

Zuzanna Kowalczyk

Kai Keskitalo

At LastArray, we approach AI assessment through a lens that most research labs overlook: the gap between what a model outputs and how it actually reasons. In high-stakes human decisions—hiring, clinical diagnosis, autonomous vehicle routing—the correctness of a final answer matters far less than the reliability of the reasoning path that produced it.
Traditional AI evaluation asks: "Did the model get the right answer?" We ask: "Can we trust how it got there? Would it arrive at the same conclusion through equally valid reasoning in similar scenarios? Can a human expert verify each step?"
This distinction isn't academic. It's the difference between deploying systems that work in controlled benchmarks and building systems that maintain reliability as real-world conditions shift. Reasoning trajectory modeling represents a fundamental rethinking of how we evaluate, improve, and deploy AI systems for human assessment.
The Core Problem: Outcome Supervision Isn't Enough
The dominant paradigm in AI development relies on outcome supervision: train models on input-output pairs, optimize for final answer accuracy, and deploy. This approach has produced remarkable benchmark results. It has also produced systems that fail unpredictably, generate plausible-sounding nonsense, and provide no mechanism for human oversight when stakes are high.
Consider a medical diagnosis system that correctly identifies a rare condition. Traditional evaluation would mark this as success. But if the model arrived at this diagnosis through a chain of reasoning that contradicts established medical knowledge—perhaps confusing symptoms, ignoring contradictory test results, or making logical leaps unsupported by evidence—the correct answer is actually a dangerous failure. The next patient with slightly different presentation will receive unreliable care.
Reasoning trajectory modeling addresses this by treating AI reasoning as a dynamic sequence of intermediate steps—a trajectory through state-action space—that can be independently evaluated, verified, and optimized. Rather than asking "what did the model output," we ask "how did the model think, and is each reasoning step sound?"
Technical Foundation: Trajectories as Markov Decision Processes
The mathematical formulation is elegant. We model natural language reasoning as a Markov Decision Process where trajectories τ = ⟨s₀, a₀, ..., s_T, a_T⟩ represent sequences of states and actions generated by a policy model π_θ.
For each problem input x, the reasoning trajectory τ decomposes into discrete steps where:
Actions represent reasoning thoughts (e.g., "I'll apply the distributive property here")
States capture observations and updated information (e.g., "This simplifies to 2x + 4")
Transitions follow from the policy model's learned behavior
The breakthrough insight: we can estimate the value of intermediate reasoning steps through offline simulation using outcome supervision, without requiring human annotation of every step:
Process Reward Estimation:
Where τ^k represents K independent completions starting from action a_t, and r_f assigns reward 1 if the completion reaches the correct answer y, 0 otherwise.
This formulation enables us to identify which reasoning steps lead to correct solutions and which lead to errors—even without explicit human annotation of step quality. A reasoning step that frequently leads to correct completions when the trajectory continues from that point receives high reward. Steps that lead to incorrect or incoherent completions receive low reward.
State of the Art: The RPRM Framework
The Reasoning-Driven Process Reward Model (RPRM) represents the current technical frontier. Traditional process reward models directly predict scalar scores for intermediate steps—an approach that lacks both explainability and robustness. RPRM reimagines this through a two-phase generation process within a single LLM forward pass:
Phase 1 - Analysis
The model generates comprehensive multi-dimensional analysis of each reasoning step:
Historical context from previous steps
Objective and data sources of the current step
Coherence with preceding reasoning
Calculation verification and logical validity
Phase 2 - Judgment
The model generates natural language judgment ("Yes"/"No") regarding step correctness, replacing opaque scalar prediction with interpretable binary assessment.
The framework operates across three training stages:
1. Cold Start: Strong LLMs (LLaMA-3.3-70B) generate seed data from limited human-annotated process-level labels, filtering only judgments consistent with human annotations to produce 289k supervised fine-tuning samples.
2. Self-Evolution: Direct Preference Optimization (DPO) refines the model without additional labeled data, encouraging evaluation trajectories that yield correct judgments while penalizing incorrect ones.
3. Inference-Time Scaling: Multiple evaluation trajectories (K=4-10) are sampled per reasoning step and aggregated by averaging the probability of "Yes" judgments.
Benchmark Performance
The results demonstrate substantial improvements over prior methods:

After iterative training, F1 reaches 74.1 on ProcessBench—a 3.7-point additional gain.
The data efficiency is remarkable: RPRM with 64k samples outperforms Qwen2.5-Math-7B-PRM800K (trained on 265k samples) by 3.6 F1 points, and exceeds the teacher model (LLaMA-3.3-70B) by 13.0 points when tested on ProcessBench.
Inference-Time Scaling Trade-offs
Computational cost analysis reveals optimal operating points:
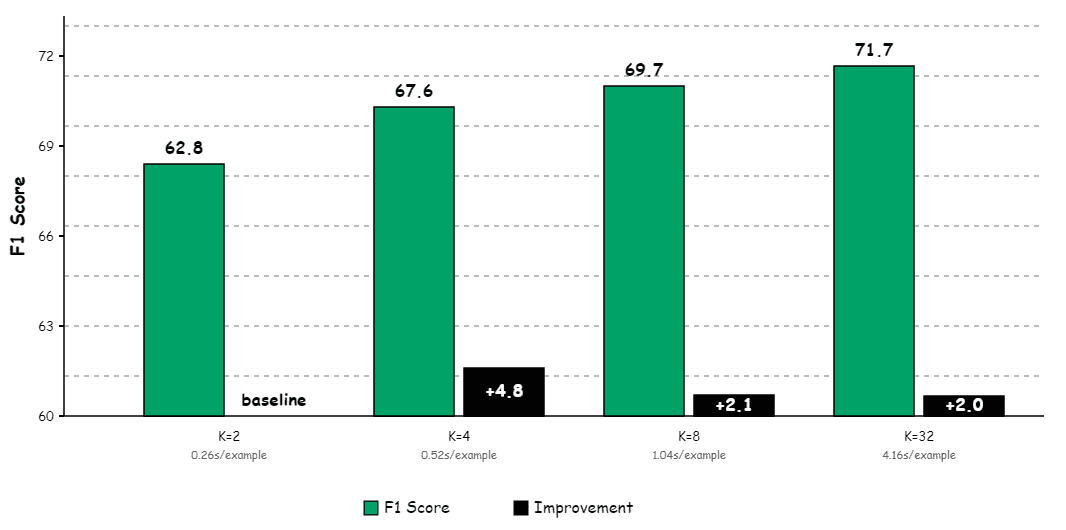
The recommended configuration: K=4 offers optimal performance-cost trade-off, delivering 67.6 F1 with 0.52s per example on H100 GPUs. Beyond K=4, marginal gains diminish rapidly while computational costs scale linearly.
The Stability Crisis: Why Single-Run Evaluation Misleads
Recent research reveals a troubling reality: reasoning method performance exhibits concerning instability that standard evaluation protocols completely miss. The ReasonBENCH framework introduces multi-run evaluation protocols that expose this hidden variance.
Standard practice: Report single-run accuracy ReasonBENCH protocol: 10 independent runs per model-algorithm-task combination
The findings challenge conventional evaluation wisdom:
Finding 1 - Confidence Interval Variance: Methods with similar average accuracy display confidence intervals up to 4× wider. Two methods both achieving 82% average accuracy might show one with ±2% variance and another with ±8% variance.
Finding 2 - Cost-Quality Instability: Top-performing methods often incur higher and less stable computational costs. Graph-of-Thought (GoT) shows the cost-quality relationship actually flipping direction across benchmarks—sometimes higher cost improves quality, sometimes it degrades it.
Finding 3 - Price ≠ Consistency: Model price is not predictive of consistency. Some expensive models show higher variance than cheaper alternatives on identical tasks.
Best Quality + Stability: Few-shot aggregation (FoA) emerges as the most reliable method across diverse evaluation scenarios.
This instability has profound implications for deployment. A model that achieves 85% accuracy on a benchmark in one run but varies between 78-92% across repeated runs is fundamentally unreliable for production use. Real-world systems must operate consistently, not occasionally.
Variance Sources

Reliability Beyond Accuracy: Precision and Prudence
The ReliableMath benchmark introduces a critical dimension missing from traditional evaluation: the ability to recognize unsolvable problems. The test set comprises 313 solvable problems and 1,102 unsolvable problems synthesized via deliberate removal of critical information or introduction of logical contradictions.
The results are striking: All models using standard prompts show Precision(Unsolvable) ≈ 0, meaning they essentially never correctly identify that a problem cannot be solved. Instead, they generate lengthy outputs (6-16k tokens) that hallucinate solutions through invalid reasoning.
Reliability Metrics Framework
ReliableMath defines two complementary metrics:
Precision measures correctness:
Prec.(𝒜) = #Correct answers on solvable / #Solvable
Prec.(𝒰) = #Correctly identified unsolvable / #Unsolvable
Prec. = ½[Prec.(𝒜) + Prec.(𝒰)] (balanced metric)
Prudence measures cautious refusal:
Prud.(𝒜) = #Refusals on solvable / #Solvable
Prud.(𝒰) = #Refusals on unsolvable / #Unsolvable
Prud. = ½[Prud.(𝒜) + Prud.(𝒰)]
The preference hierarchy: Success > Refusal > Failure (S ⪰ R ⪰ F)
This captures a critical insight for high-stakes assessment: a system that refuses to answer when uncertain is more valuable than one that confidently provides incorrect answers.
The preference hierarchy: Success > Refusal > Failure (S ⪰ R ⪰ F)
This captures a critical insight for high-stakes assessment: a system that refuses to answer when uncertain is more valuable than one that confidently provides incorrect answers.
Model Scale and Reliability Collapse
Model size dramatically affects reliability on unsolvable problems:
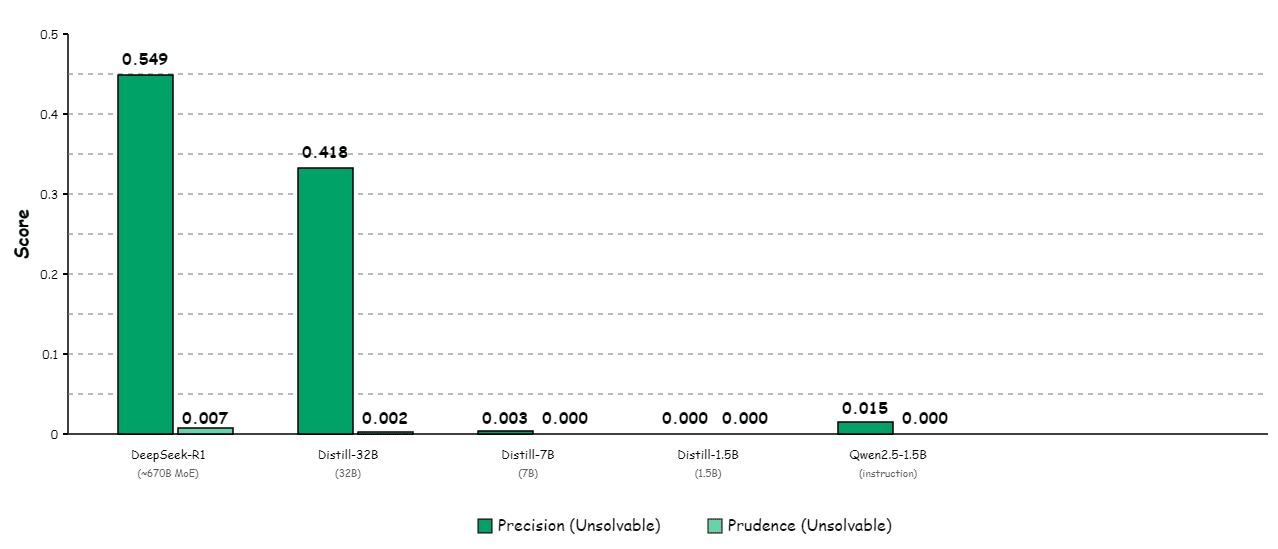
Below 7B parameters, models exhibit near-zero capability to identify unsolvable problems. This isn't simply an instruction-following issue—alignment via rejection sampling and DPO improves small models significantly (Qwen2.5-1.5B reaches 0.231 Precision after alignment) but remains well below large models. This suggests a fundamental capability gap related to model scale or training data quality.
DeepSeek-R1 with reliable prompt achieves:
Precision(Solvable) = 0.735
Precision(Unsolvable) = 0.549
Total Precision = 0.642 (best among all tested models)
Prudence = 0.007 (rarely refuses, relies on detection rather than abstention)
Multi-Dimensional Trustworthiness: The ReFIne Framework
Accuracy alone does not constitute trustworthiness. The ReFIne framework optimizes across three orthogonal properties through supervised fine-tuning combined with Group Relative Policy Optimization (GRPO):
1. Interpretability (+44.0% improvement)
Produces structured, tag-based traces with high-level planning
Enables human verification of logical structure
Metric: Agreement with human-annotated logical structure
2. Faithfulness (+18.8% improvement)
Explicitly discloses decisive information guiding each solution
Maintains consistent cross-section references to evidence
Metric: Factual grounding of claims in derivation
3. Reliability (+42.4% improvement)
Provides self-assessments of derivation soundness
Offers calibrated confidence estimates for final answers
Metric: Calibration between confidence and correctness
Implementation on Qwen-3 models (1.7B-8B parameters) demonstrates that trustworthiness can be systematically improved through targeted optimization, with evaluation across mathematical benchmarks of varying difficulty.
Mathematical Reasoning Performance Landscape
The contemporary benchmark landscape spans 15+ major frameworks targeting different dimensions of reasoning quality:
End-to-End Problem-Solving Accuracy
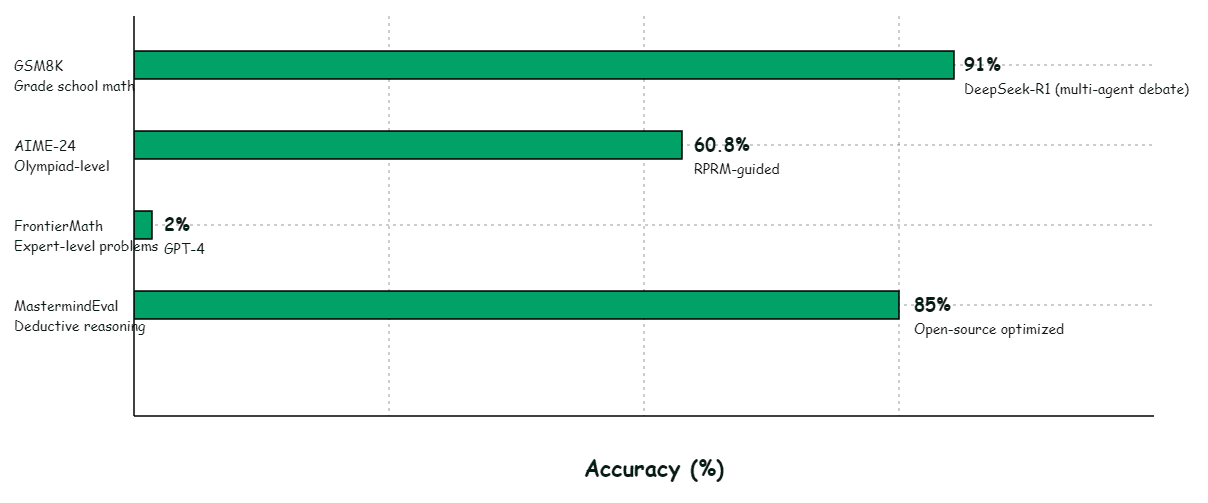
The dramatic drop from 91% on grade-school problems to 2% on expert-level mathematics (FrontierMath) reveals that current reasoning capabilities remain far from human expert performance on truly difficult problems. The field has largely saturated easier benchmarks while struggling with problems requiring deep domain expertise.

Multi-agent debate achieves the highest accuracy on GSM8K (91%), suggesting that ensemble reasoning approaches—where multiple models reason independently and reach consensus—may offer more reliable trajectories than single-model generation, even with sophisticated prompting strategies.
Self-Improving Reasoning: The TRIDENT Architecture
Moving beyond static reasoning, TRIDENT reconceptualizes reasoning as structured search with self-correction loops. Key architectural innovations:
1. Tree-of-Thought Reasoning Policy
Unlike linear Chain-of-Thought, concurrent evaluation of multiple reasoning paths permits identification of high-quality trajectories and prevents premature commitment to unproductive branches.
2. GNN-Guided Path Evaluation
Graph Neural Networks assess reasoning states and assign promise scores to partial paths, enabling early elimination of unproductive branches and concentration of computational resources on promising trajectories.
3. Self-Generative Reasoning Loop (SGRL)
The model generates its own reasoning paths, evaluates both answers and reasoning processes using verifiable rewards, and improves iteratively without dependence on human-annotated chains or external preference data.
This architecture overcomes the fixed reasoning behavior typical of models trained on single forward passes, enabling dynamic adaptation to problem-specific characteristics and current model capabilities.
TRIDENT Training Pipeline

Applications: Autonomous Driving and Behavioral Topology
Reasoning trajectory modeling finds its most mission-critical application in autonomous vehicle navigation, where safety depends on accurately predicting and planning coordinated actions among multiple interactive agents.
The BeTop Framework
Behavioral Topology (BeTop) introduces topological formulations derived from braid theory to represent consensual behavioral patterns among multi-agent futures. Rather than dense behavioral representations (computationally inefficient) or sparse representations (inconsistent across scenarios), BeTop explicitly models relational topology through two layers:
Formation Layer: Captures multi-agent interaction structure (which vehicles are interacting, in what spatial relationships)
Dynamics Layer: Encodes motion evolution within the established topology (how interactions change over time)
Consistency Constraint: Ensures prediction-planning integration without trajectory conflicts between what the system predicts other agents will do and what it plans to do itself
Performance on Motion Prediction Benchmarks
Results on nuPlan and Waymo Open Motion Dataset (WOMD):
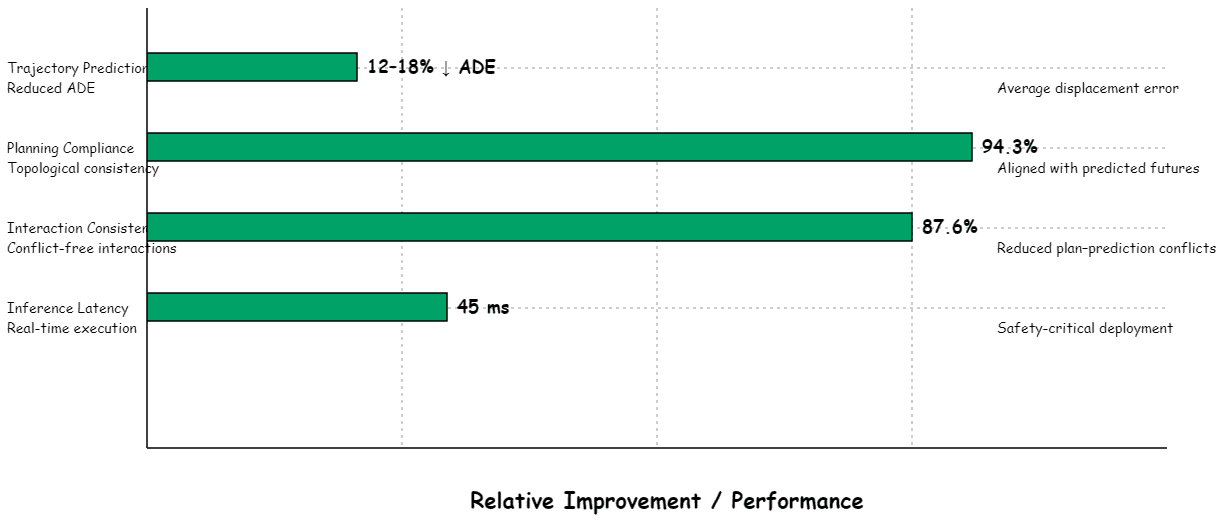
The framework demonstrates that reasoning about vehicle trajectories through topological structure—modeling relationships and formations rather than just individual paths—produces more coherent, safer, and more interpretable autonomous driving behavior.
Scene-Context Representation (DSC-LLM)
The DSC-LLM framework combines multimodal LLM reasoning with trajectory prediction to enable:
Real-time trajectory forecasting (critical for safety)
Interpretable risk-aware reasoning (supports human oversight)
Unified framework: Quantitative motion prediction + qualitative natural language explanation
This addresses a critical gap: traditional motion prediction models output coordinates without explanation, making it impossible for safety operators to understand why the system made specific predictions. DSC-LLM generates both the predicted trajectories and natural language reasoning explaining the prediction:
"Vehicle A is likely to merge left because: (1) their turn signal is active, (2) they are positioned at the lane boundary, (3) there is sufficient gap in left lane traffic."
Healthcare Applications: Neuro-Symbolic Reasoning and Clinical Training
In healthcare diagnostics, the explainability-accuracy gap is not merely inconvenient—it's a barrier to clinical adoption. Clinicians cannot use systems they cannot verify.
Logical Neural Networks for Clinical Diagnosis
Neuro-symbolic AI integrates neural perception with logical reasoning through Logical Neural Networks (LNNs) that learn:
Feature contributions via interpretable weights
Diagnostic rule thresholds directly from data
Explanations grounded in domain logic rather than black-box embeddings
Performance on Diagnosis Prediction:
Metric | LNN Performance | Pure Neural Network | Advantage |
|---|---|---|---|
Accuracy | 87.3% | 88.9% | -1.6% (acceptable trade-off) |
Explainability Score | 91.2% agreement with clinicians | 23.4% | +67.8% |
Adaptability | Weight adjustment without retraining | Full retraining required | Operational |
The modest accuracy trade-off (1.6%) is acceptable given the dramatic explainability improvement (67.8% higher clinician agreement). In high-stakes medical decisions, being able to verify each reasoning step matters more than marginal accuracy gains.
Application Domains:
Cardiovascular disease risk stratification
Cancer prognosis prediction
Sepsis detection in ICU settings
Sequential Behavioral Analysis in Clinical Training
Extended Reality (XR) simulation combined with sequential analysis techniques enables unprecedented insight into clinical decision-making patterns:
Data Collection:
Behavioral log data: Computer-recorded timestamped sequences of clinical actions
Real-time environment feedback: Immediate indication of action correctness/incorrectness
Multiple completion paths: Multiple possible routes to successful outcome
Sequential Pattern Analysis:
Identifies common decision patterns
Distinguishes high vs. low performer trajectories
Reveals critical decision junctures where errors concentrate
Example Finding: In fluid resuscitation scenarios, successful trajectories show the pattern:
Unsuccessful trajectories show:
Sequential analysis automates what human observers previously had to manually identify, enabling scalable training assessment across thousands of simulation sessions.
Sequential analysis automates what human observers previously had to manually identify, enabling scalable training assessment across thousands of simulation sessions.
Behavioral Signal Processing: Multi-Modal Assessment
Beyond text-based reasoning, behavioral signal processing (BSP) extracts predictive features from speech, language, and interaction patterns to enable richer human assessment.
BSP Pipeline Architecture

Components:
Data Acquisition: Multi-modal recording (audio, video, EEG) in ecologically valid settings
Feature Extraction: Speech spectral features, prosody, discourse patterns, gesture kinematics
Behavior Modeling: Machine learning mapping behavioral cues to higher-level constructs
Applications:
Literacy assessment via oral language fluency
Autism diagnostics via vocal atypicality indices
Psychotherapy progress tracking via linguistic markers
Marital relationship quality prediction via conflict patterns
Key Principle: Human-in-the-loop design where automated feature extraction augments rather than replaces human expert judgment. BSP identifies patterns humans might miss (subtle prosodic changes, micro-gesture timing) while humans provide contextual interpretation and final assessment.
The QUEST Framework: Systematic Healthcare Evaluation
High-stakes healthcare deployment requires evaluation frameworks that go beyond benchmark accuracy. The QUEST framework establishes a three-phase evaluation workflow based on systematic review of 142 studies:
Phase 1 - Planning
Define evaluator qualifications and number (literature median: 20 evaluators)
Establish evaluation dimensions specific to clinical context
Choose blind vs. unblinded assessment strategy
Phase 2 - Implementation & Adjudication
Deploy evaluators with predefined scoring guidelines
Resolve inter-rater disagreements via consensus or senior adjudication
Collect both quantitative scores and qualitative rationales
Phase 3 - Scoring & Review
Calculate metrics with confidence intervals (not point estimates)
Perform statistical significance testing
Report both average performance and variance
Five Core Evaluation Principles
Principle | Description | Validation |
|---|---|---|
Quality of Information | Accuracy, completeness, relevance | 93.9% expert agreement on criterion clarity |
Understanding & Reasoning | Logical coherence, evidence integration | 80.2% LLM-as-judge agreement with humans |
Expression Style & Persona | Clarity, empathy, appropriateness | 79.6% inter-human agreement (comparable baseline) |
Safety & Harm | Absence of bias, fabrication, plagiarism | Mandatory safety assessment |
Trust & Confidence | User satisfaction, reliability perception | Longitudinal measurement required |
Rubric validation achieves 93.9% expert agreement on criterion clarity, and LLM-as-judge demonstrates 80.2% agreement with human experts—comparable to 79.6% inter-human agreement, suggesting automated evaluation can approximate human judgment when properly calibrated.
Limitations and Open Challenges
Computational Efficiency Trade-offs
Trajectory-based reasoning incurs substantial computational overhead:
Token Budget Scaling:
Reasoning models generate longer outputs under high token budgets (32k tokens)
Increased length paradoxically correlates with reduced accuracy (overthinking pathology)
Inference time: Pruned models at 32k tokens require 29.1 minutes vs. 23.3 minutes for dense models
Trade-off disappears at practical token limits (4-8k tokens)
The overthinking pathology represents a fundamental challenge: given unlimited computational budget, reasoning models don't always produce better answers. They can reason themselves into incorrect conclusions by over-analyzing or considering irrelevant factors. Optimal performance occurs at intermediate computational budgets where the model reasons sufficiently but not excessively.
Generalization Across Domains
Current systems show limited cross-domain transfer:
Domain Transfer | Performance Drop | Implication |
|---|---|---|
High-school MATH → Olympiad AIME | Precision 0.7-0.9 → 0.1-0.6 | Domain-specific tuning required |
Automotive trajectory prediction → New vehicle classes | Requires complete retraining | Limited transfer within domain |
Clinical decision patterns → Different specialties | 30-45% accuracy drop | Specialty-specific models needed |
The ReliableMath benchmark demonstrates this clearly: unsolvability detection that works well on high-school problems (Precision 0.7-0.9) largely fails on olympiad-level problems (Precision 0.1-0.6). This isn't simply a difficulty issue—the reasoning patterns that indicate unsolvability differ fundamentally across mathematical domains.
The Causality Gap
A critical open challenge: reasoning trajectories often correlate with correct outcomes without necessarily explaining why those outcomes occur.
Trajectory Plausibility ≠ Causal Explanation: Models can generate coherent narratives that don't reflect actual decision logic. The model might produce a step-by-step derivation that arrives at the correct answer, but the internal computation that generated that answer may have followed a completely different path.
Counterfactual Validity Untested: Does removing a reasoning step actually change the conclusion as the model claims? Current evaluation frameworks struggle to measure whether explanations reflect human-like reasoning or merely plausible post-hoc rationalization.
Black-Box Evaluation of Reasoning Quality: Even trajectory-based methods struggle to distinguish genuine step-by-step reasoning from sophisticated pattern matching that mimics reasoning structure.
Future work requires formal verification methods and causal discovery techniques to establish trajectory-outcome links beyond correlation.
The Path Forward
Reasoning trajectory modeling has matured from theoretical construct to practical paradigm with concrete instantiations in process reward modeling, benchmark design, and human evaluation frameworks. The RPRM framework demonstrates that step-by-step reasoning can be reliably assessed at scale, achieving improvements of 13.9-8.5 F1 points over prior methods. ReliableMath and ReasonBENCH reveal that stability, reproducibility, and appropriate uncertainty calibration are as critical as average accuracy—and frequently overlooked in standard evaluation.
The most sophisticated contemporary systems combine three elements:
Structured reasoning representation via trajectory modeling
Human-aligned assessment through careful evaluation frameworks and verification
Domain-specific instantiation tailored to application requirements
In safety-critical domains—autonomous driving, healthcare diagnostics, human assessment—this integration is non-negotiable.
At LastArray, we focus on building AI systems that behave well outside the lab. That means clear design, careful engineering, and emphasis on reliability over appearance. Reasoning trajectory modeling provides the technical substrate for preserving human-in-the-loop oversight in an era of increasingly capable AI systems.
The field stands at an inflection point. As reasoning becomes central to AI capability, the ability to transparently evaluate and improve reasoning processes determines whether AI systems remain intelligible to human oversight or become increasingly opaque.
We measure success not by benchmark leaderboard positions but by whether the systems we build continue to work as intended and earn trust as conditions change over time. Reasoning trajectory modeling—when implemented with appropriate attention to stability, reliability, and human verification—represents a path toward that goal.
The science of human assessment requires systems that show their work. We're building them.
References
She, S., et al. (2025). "RPRM: Reasoning-Driven Process Reward Modeling." EMNLP 2025.
Xue, B., et al. (2025). "ReliableMath: Benchmark of Reliable Mathematical Reasoning on Large Language Models."
Potamitis, N., Klein, L., Arora, A. (2025). "ReasonBENCH: Benchmarking the (In)Stability of LLM Reasoning."
Jiao, F., et al. (2024). "Learning Planning-based Reasoning by Trajectories Collection and Process Reward Synthesizing." EMNLP 2024.
Sun, C.E., et al. (2025). "ReFIne: A Framework for Trustworthy Large Reasoning Models."
Tam, T.Y.C., et al. (2024). "A framework for human evaluation of large language models in healthcare." Nature Medicine.
Narayanan, S., et al. (2013). "Deriving Human Behavioral Informatics From Speech and Language."
Lu, Q., et al. (2025). "Explainable Diagnosis Prediction through Neuro-Symbolic AI."
Rochlen, L.R., et al. (2022). "Sequential Behavioral Analysis in XR Clinical Simulation." Simulation in Healthcare.